
Contexto
El movimiento DevOps tienes su raíces incluso antes del 2009 pero fue con el libro Continuous Delivery de Jez Humble, publicado a fines del 2010, que estas prácticas estuvieron disponibles para todos. A pesar de eso, estas prácticas eran principalmente usadas en organizaciones Cloud Native o Unicornios (startups a la vanguardia en innovación). Quizás fue con la publicación del libro The Phoenix Project de Gene Kim, más de una década después, que las empresas tradicionales empezaron a querer obtener los beneficios que una adopción DevOps promete.
El siguiente artículo describe una forma de iniciar con la adopción DevOps especialmente en empresas de gran tamaño.
Problema
Iniciar con la adopción DevOps, especialmente en empresas de mayor tamaño, presenta retos particulares. Estos incluyen la necesidad de estandarizar prácticas, plataformas y procesos para replicarse en el resto de la organización, el apoyo de la dirección para cambiar la rigidez de procesos existentes y la inercia organizacional existente. Esto hace más difícil lograr una implementación exitosa de este cambio.
¿Cómo iniciar la adopción DevOps?
El primer paso para iniciar este proceso es saber a dónde queremos llegar. Como nos recuerda el gato de Alicia en el país de las maravillas, “Si no sabes adónde quieres ir, no importa qué camino sigas”. Para identificar correctamente a dónde queremos llegar, debemos entender por qué queremos adoptar DevOps y cuál es nuestra meta, es decir entender cuáles son las metas del negocio que deseamos potenciar. Quizás el objetivo sea incrementar la velocidad con la que lanzamos nuevas versiones de nuestras aplicaciones, potenciar la innovación o mejorar la calidad de nuestras aplicaciones. Además de saber a dónde queremos llegar, también debemos entender nuestras capacidades actuales, o dónde estamos actualmente, de modo que podamos implementar el plan de adopción que nos permita llegar al objetivo.
Las acciones en este plan deben buscar mejorar cuatro áreas centrales:
- Mejora de procesos: ¿Cómo hacer nuestro proceso eficiente reduciendo desperdicios?
- Herramientas de automatización: ¿Cómo automatizar estos procesos de mejora, para hacerlos repetibles, escalables y reducir los errores?
- Plataformas y ambientes: ¿Cómo hacer resilientes, elásticos, escalables y configurables las plataformas y ambientes de todo nuestro proceso de entrega? Incluyendo desde toma de requerimientos hasta el despliegue.
- Cultura: ¿Cómo fomentar una cultura de confianza, comunicación y colaboración?
En su libro The DevOps Adoption Playbook, Sanjeev Sharma propone la siguiente manera de construir este plan.

Identificar la meta (¿A dónde queremos llegar?)
Las áreas de TI existen para ayudar a las líneas de negocio de la organización a través de proveer servicios y soluciones con las siguientes características:
- Velocidad
- Agilidad
- Innovación
- Calidad
- Bajo costo
Aunque estas características, pueden variar de organización en organización e incluso de equipo en equipo, estas deben ser convertidas en indicadores que reflejen la capacidad del equipo para lograr estas metas. Algunos de estos indicadores pueden ser:
- Velocidad de despliegues
- Reducción de costo/tiempo para el despliegue
- Reducción de errores ocasionados por los despliegues
- Minimizar los rollbacks
Como punto de partida, el reporte 2017 State of Devops de Puppet, que se construye sobre la base del análisis de datos de organizaciones de alto rendimiento, concluye que son principalmente cuatro métricas importantes que separan a los equipos de alto rendimiento el resto:
- Lead Time (medido desde que el requerimiento entra en nuestro backlog hasta que es desplegado)
- Frecuencia de despliegue
- Tiempo de recuperación (MTTR)
- Porcentaje de fallas provocado por los despliegues
Identificar el estado actual (¿En dónde estamos?)
Para identificar el estado de madurez actual deben realizarse ciertas preguntas sobre las capacidades de nuestra organización:
- ¿Somos capaces de crear nuevas e innovadoras aplicaciones y aprovechar arquitecturas modernas?
- ¿Somos capaces de modernizar aplicaciones existentes para permitir entregas más rápidas e innovadoras?
- ¿Somos capaces de adaptar su cultura, procesos y herramientas para lograr sus objetivos?
Para poder atacar estos retos debemos seguir un proceso de 3 pasos:
- Identificar las ineficiencias y desperdicios
- Identificar las causas raíz de estas ineficiencias y desperdicios
- Crear el plan de acción para atacar estas causas
Identificar las ineficiencias y desperdicios
Una de las mejores formas de identificar los desperdicios e ineficiencias es el uso del Value Stream Mapping o VSM. Esta es una técnica Lean que permite analizar, diseñar y administrar el flujo de materiales e información requeridos para brindar un producto a un cliente. Esta permite analizar nuestro proceso de entrega para identificar los desperdicios, o las actividades que no generan valor. Este desperdicio se manifiesta de diferentes maneras:
- Pasos innecesarios
- Retrabajo
- Esperas
- Actividades manuales
- etc.
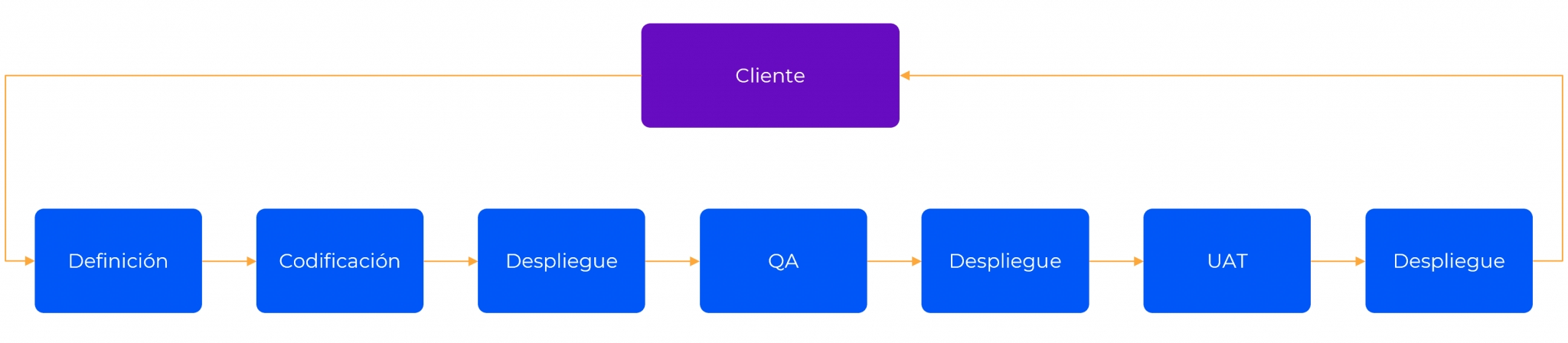
La mayor parte de los desperdicios ocurren durante la transferencia de los artefactos, es decir cuando los resultados de una tarea son recibido por otro stakeholder, área o parte en el proceso. Este aparece como esperas, porque el artefacto es rechazado porque está en el formato incorrecto o no cumple con las especificaciones de este (ej.: Bugs en una aplicación, datos en un formato incorrecto, etc.). En el contexto de DevOps, un ejercicio de VSM implica analizar el proceso de entrega desde la toma de requerimientos hasta despliegue de la aplicación. Un buen proceso de DevOps debería reducir los desperdicios, removiendo el trabajo que no agrega valor, haciendo el proceso más eficiente de forma continua.
Dependiendo del caso particular de nuestra organización, se puede realizar un VSM a nivel profundo, ejercicio de varios días con tomas de medidas de tiempos y ratios específicos, o un VSM a alto nivel, donde solo se identifican los cuellos de botella. Cualquiera sea el caso, es importante que los principales stakeholders del proceso participen en este taller de modo que se puedan identificar correctamente los cuellos de botella.
Identificar las causas raíz de estas ineficiencias y desperdicios
Una vez realizado el VSM, se debe realizar un análisis de causa raíz de cada uno de los cuellos de botella identificados. Estas causas raíz serán el foco del plan de acción de tu plan de adopción DevOps. Un método muy utilizado para identificar las causas raíz es el uso de 5 Por qués utilizando el diagrama de Ishikawa, que permite ir más allá de los síntomas e identificar la fuente del problema.
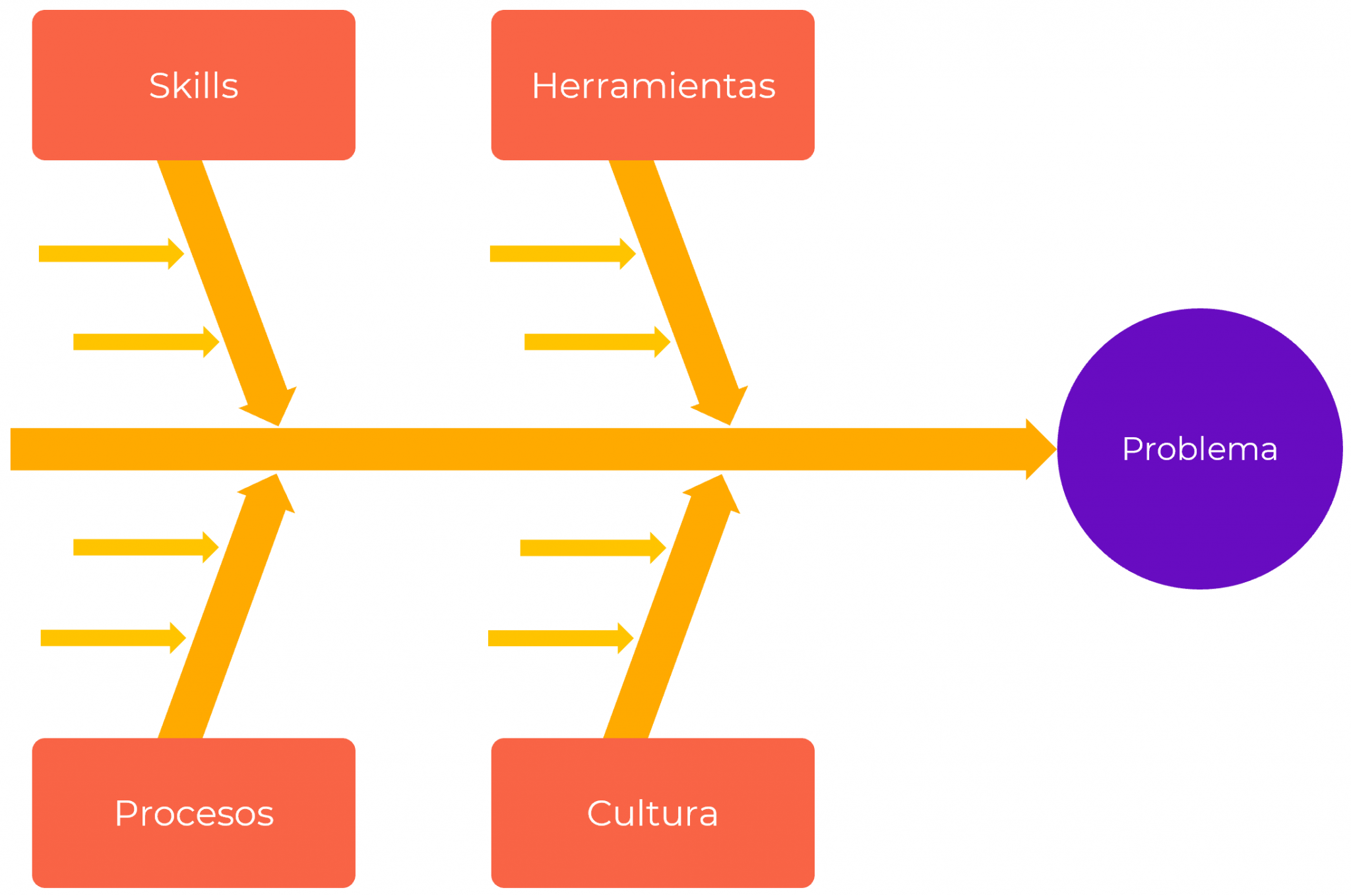
Algunos de los problemas comúnmente identificados son:
- Falta de integración de herramientas que producen esperas mientras los artefactos son promovidos de una herramienta a la otra
- Falta de visibilidad de los miembros del equipo respecto al trabajo de los otros
- Dificultad en colaborar con el trabajo de otros miembros del equipo
- Múltiples ambientes desconectados y no compatibles con el ambiente de producción
- Múltiples stacks tecnológicos administrados de forma independiente y distinta
Crear el plan de acción para atacar estas causas
Una vez identificadas las causas raíz de los cuellos de botella, el siguiente paso es identificar cuáles son las capacidades DevOps que permitan resolverlas. Para determinarlas debe tenerse en cuenta varios factores de negocio, técnicos y organizacionales, como:
- Capacidad del equipo para adaptarse a los cambios de herramientas y procesos
- Capacidad de la organización para adaptarse al cambio organizacional
- Recursos disponibles para financiar el cambio
- Fechas del proyecto
- Tiempo esperado para ver resultados
- Nivel de apoyo del equipo líder de la organización
Cada una de las acciones identificadas deben atacar las 4 áreas centrales antes mencionadas, mejora de procesos, herramientas de automatización, plataformas y ambientes, y cultura. Es muy importante también que este plan considere cómo tratar dos aspectos que pueden tener un impacto negativo en la adopción DevOps, el impacto inicial en productividad y la inercia organizacional.
Impacto inicial en la productividad
Siempre que se pasa por un proceso de transformación existe una caída inicial en productividad antes de generar un incremento. Esto es un resultado natural de los cambios introducidos en las herramientas, procesos y estructura de la organización. Esta caída es recuperada luego con los beneficios obtenidos por estos cambios, y es por eso muy importante tener un proceso de transformación adecuadamente planificado y la participación de coaches con experiencia en proceso de transformación.
La otra buena práctica es iniciar la adopción con algunos proyectos piloto, y solo una vez probado el resultado del plan (mejorado con las lecciones aprendidas de los pilotos), escalar este plan a toda la organización. Se recomienda que cada piloto implemente solo una de las acciones identificadas en el plan, de modo que se pueda medir el impacto de esta acción para resolver el cuello de botella específico. Es muy importante también identificar los indicadores adecuados para medir el impacto de cada acción. Estos indicadores se deben definir de antemano, y realizar una medición de línea base antes de implementar las acciones. Luego se debe monitorear el cambio en estos indicadores, sea bueno o malo, de modo que se pueda ajustar el plan. Los mejor es seleccionar proyectos piloto que sean importantes para la organización, pero no críticos, de modo que tengan el apoyo y financiamiento adecuado pero que no impacte un proceso de negocio crítico, de haber demoras o requerir ajustes en la implementación del plan.
Inercia organizacional
Incluso al haber introducido los cambios adecuados en procesos, herramientas y estructura organizacional, y habiendo seleccionado los pilotos adecuados, este cambio solo será exitoso si logra vencer la inercia organizacional. La mayor parte de las organizaciones poseen un rechazo natural al cambio, especialmente en organizaciones grandes, donde la forma de hacer las cosas no ha cambiado en años. Estos comportamientos se pueden apreciar en respuestas como “eso es responsabilidad de otra área”, procesos que nadie entiende la razón por la que se hacen (pero que tampoco cuestionan el hacerlo) o reportes que se hacen aun cuando ya nadie los revisa. Todos estos comportamientos convierten a la inercia organizacional en parte de la cultura de la organización.
Para poder vencer esta inercia todo proyecto de implementación DevOps debe aplicar un enfoque desde arriba y desde abajo, apoyo del equipo líder de la organización desde arriba para liderar y fomentar el cambio y un equipo muy involucrado desde abajo para ejecutar la transformación.
Conclusión
Para realizar una adopción DevOps exitosa se debe conocer adecuadamente los objetivos del negocio y el estado actual de nuestra organización, para conocer sus fortalezas y debilidades y finalmente construir un plan de acciones. Estas acciones deben ser luego ejecutadas y medida su efectividad, para poder corregirlas y mejorarlas. Esta adopción requiere:
- Identificar el estado final deseado
- Entender el estado actual
- Seleccionar las acciones adecuadas para llegar del estado actual al estado final
- Prepararse para manejar el impacto inicial en la productividad
- Trabajar con un enfoque de liderazgo desde arriba y un equipo involucrados desde abajo para lograr superar la inercia organizacional

