
Comprehensive monitoring is a must now that development moves faster than ever
The cloud has transformed the economics of infrastructure, essentially crumbling the barrier to entry for building applications on world-class technology. It has brought about a fundamental change on the operations side as well: the effortless scaling made possible by the cloud means that the typical organization’s infrastructure is always in flux.
In the following chapters, we will outline a practical monitoring framework for dynamic infrastructure. This framework comes out of our experience monitoring large-scale infrastructure for thousands of customers, as well as for our own rapidly scaling application in the cloud.
Most infrastructure monitoring data falls into one of two categories: metrics and events.
Metrics capture a value pertaining to your systems at a specific point in time. There are two important categories of metrics:
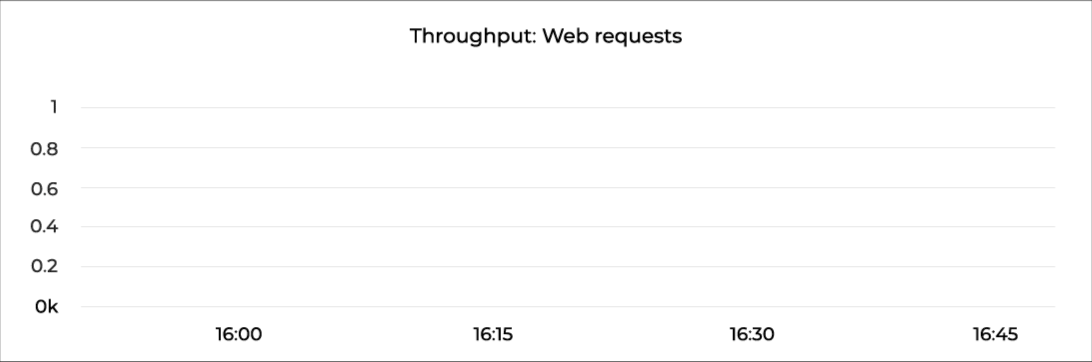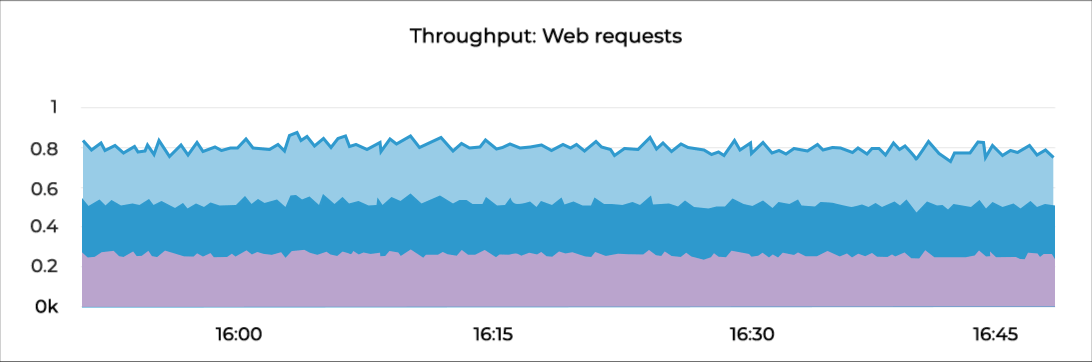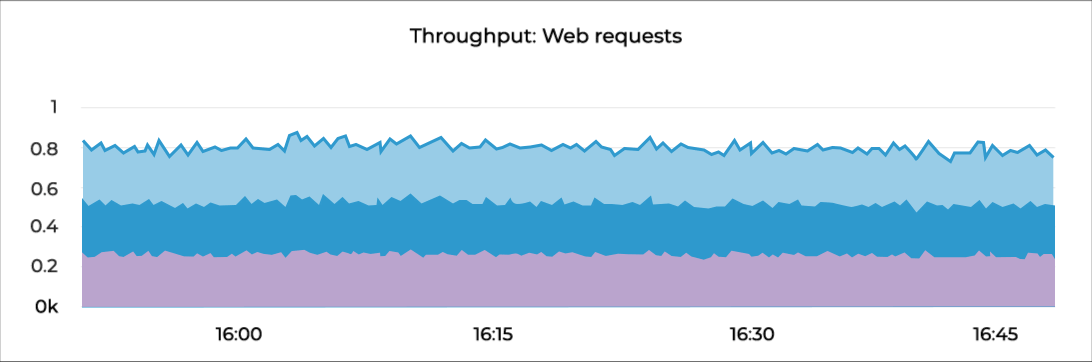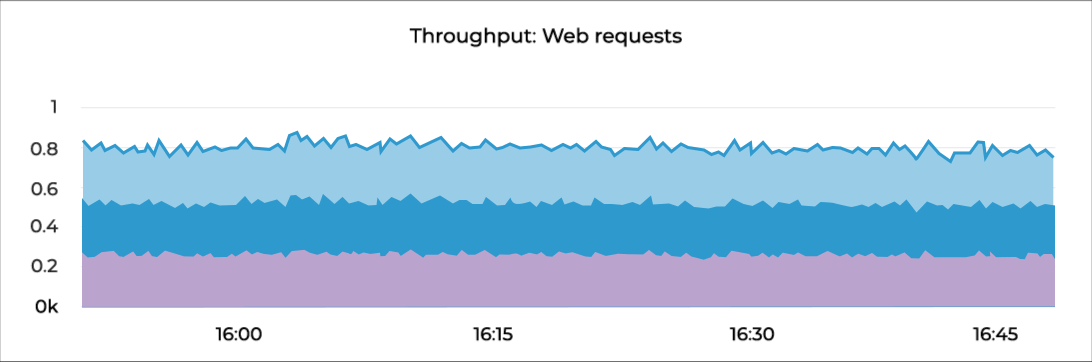
Indicate the top-level health of your system by measuring its useful output and are invaluable for surfacing real, often user-facing issues.
Metric Type | Description | Example (Web server) |
|---|---|---|
Throughput | The amount of work completed per unit time | Requested per second |
Success | The portion of work executed successfully | 2XX Responses / Total responses |
Error | The number, rate, or percentage of erroneous results | 5XX Responses / Total responses |
Performance | Measurement of how efficiently a component is doing its work | 95TH Percentile response time |
Metric Type: Throughput
Description: The amount of work completed per unit time
Example (Web server): Requested per second
Metric Type: Success
Description: The portion of work executed successfully
Example (Web server): 2XX Responses / Total responses
Metric Type: Error
Description: The number, rate, or percentage of
erroneous results
Example (Web server): 5XX Responses / Total responses
Metric Type: Performance
Description: Measurement of how efficiently a
component is doing its work
Example (Web server): 95TH Percentile response time
Most components of your infrastructure serve as a resource to other systems and are especially valuable for investigating problems.
Metric Type | Description | Example (Web server) |
|---|---|---|
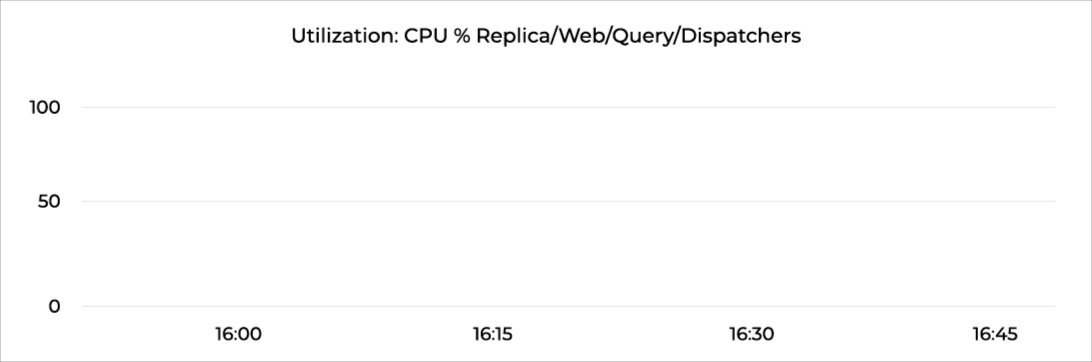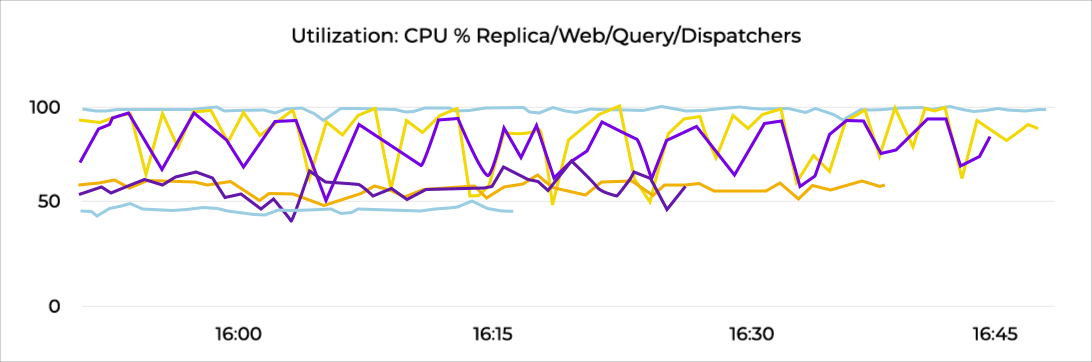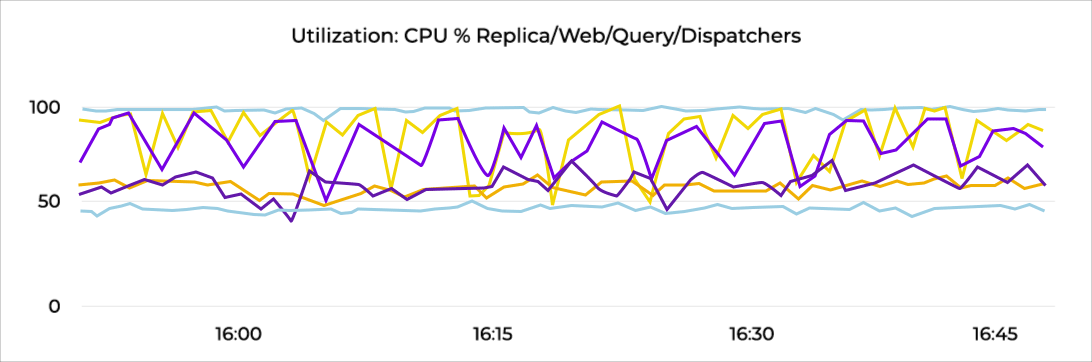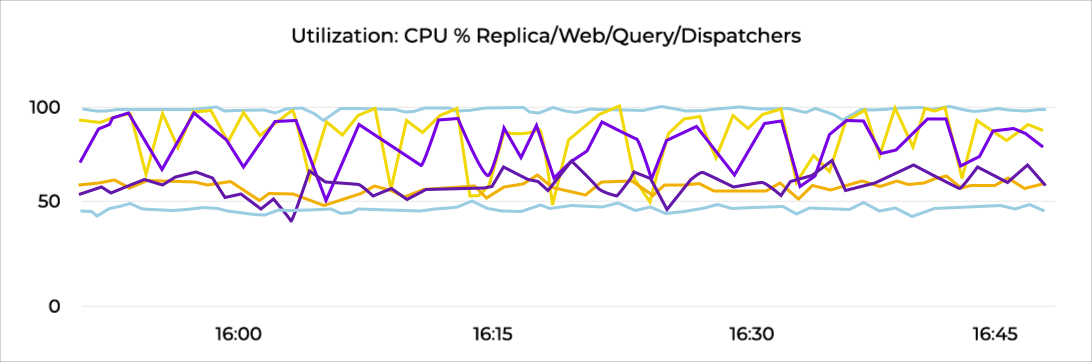
Utilization | The percentage of time that the resource is busy or how much of the resource’s capacity is in use | Open database connections |
Saturation | The amount of requested work that the resources cannot yet service | Disk queue depth |
Error | Internal errors that may not be observable in the work the resources produces | Failed connection attempts |
Availability | The percentage of time that the resource responded to requests | N/A |
Metric Type: Utilization
Description: The percentage of time that the resource is busy or how muchof the resource’s capacity is in use
Example (Web server): Open database connections
Metric Type: Saturation
Description: The amount of requested work that the resources cannot yet service
Example (Web server): Disk queue depth
Metric Type: Error
Description: Internal errors that may not be observable in the work the resources produces
Example (Web server): Failed connection attempts
Metric Type: Availability
Description: The percentage of time that the resource responded to requests
Example (Web server): N/A
In contrast to metrics, which are collected more or less continuously, events are discrete, infrequent occurrences. Events capture what happened, at a point in time, with optional additional information. These provide crucial context for understanding changes in your system’s behavior.

Automated alerts allow you to spot problems anywhere in your infrastructure, so that you can rapidly identify their causes and minimize service degradation and disruption. Know the levels of alerting urgency:

Many alerts will not be associated with a service problem, so a human may never even need to be aware of them.
The next tier of alerting urgency is for issues that do require intervention, but not right away.
The most urgent alerts should receive special treatment and be escalated to a page (as in "pager") to urgently request human attention.
Investigating is often the least structured aspect of monitoring, driven largely by hunches and guess-and-check. This chapter describes a more directed approach for finding and correcting root causes.

First examine the work metrics for the highest-level system that is exhibiting problems. These metrics will usually set the direction for your investigation

Next examine the system's resources-physical resources as well as services that support the system. Well-designed dashboards enable you to quickly scan relevant resource metrics for each system.

Next consider events that may be correlated with your metrics. Look for code releases, internal alerts, or other events that were recorded just before the problem developed.

Once you have determined what caused the issue, correct it. Your investigation is complete when symptoms disappear.
To keep your investigations focused, set up dashboards in advance. You may
want to set up one dashboard for your high-level application metrics, and
one dashboard for each subsystem.




Clicking " Send", you agree that bit2bit Americas will store and process the personal information provided above in order to give you the requested content.
2024 © bit2bit Americas.
Usuario Avanzado
Usuario Básico
Usuario Avanzado
Usuario Básico
Administrador
Administrador
Usuario Avanzado
Usuario Básico
Administrador
Usuario Básico
Usuario Avanzado
Usuario Básico
Despliegue
Usuario Avanzado
Bitbucket Cloud Usuario Básico
What are ITSM processes? ITIL version 4 recently went from recommending ITSM “processes” to introducing 34 ITSM “practices”. Their reasoning for this updated terminology is that “elements such as culture, technology, information and data management can be considered to get a holistic view of ways of working”. This more comprehensive approach better reflects the realities of modern organizations.
Here, we will not concern ourselves with nuanced differences in the use of practice or process terminology. What’s important and true, no matter what framework your team follows, is that modern IT service teams use organizational resources and follow repeatable procedures to deliver consistent and efficient service. In fact, leveraging practice or process is what distinguishes ITSM from IT.
Change management ensures standard procedures are used for efficient and prompt handling of all changes to IT infrastructure, whether it’s rolling out new services, managing existing ones, or resolving problems in the code. Effective change management provides context and transparency to avoid bottlenecks, while minimizing risk. Don’t feel overwhelmed by these and the even longer list of ITIL practices.
Problem management is the process of identifying and managing the causes of incidents on an IT service. Problem management isn’t just about finding and fixing incidents, but identifying and understanding the underlying causes of an incident as well as identifying the best method to eliminate the root causes.
Incident management is the process to respond to an unplanned event or service interruption and restore the service to its operational state. Considering all the software services organizations rely on today, there are more potential failure points than ever, so this process must be ready to quickly respond to and resolve issues.
IT asset management (also known as ITAM) is the process of ensuring an organization’s assets are accounted for, deployed, maintained, upgraded, and disposed of when the time comes. Put simply, it’s making sure that the valuable items, tangible and intangible, in your organization are tracked and being used.
Is the process of creating, sharing, using, and managing the knowledge and information of an organization. It refers to a multidisciplinary approach to achieving organizational objectives by making the best use of knowledge.
Is a repeatable procedure for handling the wide variety of customer service requests, like requests for access to applications, software enhancements, and hardware updates. The service request workstream often involves recurring requests, and benefits greatly from enabling customers with knowledge and automating certain tasks.
It’s simply not enough to have an ITSM solution – you need one that actually accelerates how your teams work.
Atlassian’s ITSM solution unlocks IT at high- velocity by streamlining workflows across development and operations at scale. Meaning what was once many siloed teams with different ways of working, are now integrated and much more collaborative than ever before.
ITSM benefits your IT team, and service management principles can improve your entire organization. ITSM leads to efficiency and productivity gains. A structured approach to service management also brings IT into alignment with business goals, standardizing the delivery of services based on budgets, resources, and results. It reduces costs and risks, and ultimately improves the customer experience.